|
OLAP
top
Konzept
OLAP = OnLine Analytical Processing
Ein weitere Ansatz OLAP-Leistung zu definieren ist das FASMI-Konzept (1995) von
Creeth und Pendse den "Erfindern" des OLAP-Reports (FASMI = Fast Analysis of Shared
Multidimensional Information) wobei ....
Fast = Antwortzeiten zu Anfragen < 5 Sek., Einfache < 1, komplexe
< 20.
Analysis = das System muß notwendige analytische Funktionen ohne
Programmierung beherrschen
Shared = das System garantiert einen Mehrbenutzerbetrieb mit
entsprechenden Schutzmechanismen.
Multidimensional = das System muß multidimensionale Sichten, Dimensionen,
Hierarchien garantieren
Information = das System muß aus Daten Informationen bilden
können
Kernpunkt der OLAP-Struktur ist der Ansatz, daß
auszuwertende Informationsgrößen (Fakten,
Variablen oder Kennzahlen genannt) von Dimensionen bestimmt werden (Zeit,
Geographie, Organisation ...), über die hinweg die Fakten analysiert werden. Das bedeutet technisch, daß in
einem solchen System mehr Redundanz herrscht als in einem normalisierten System (der Name eines Produktleiters
wird n-mal in einer Dimension gespeichert, auch wenn er sich von einer Produktlinie ableiten
ließe).
Diese Methode entspricht aber eher der menschlich logischen Denkweise, die damit
schneller als in einem normalisierten System umsetzbar ist. So entspricht eine klassische 2-achsige
Tabellenkalkulation 2 Dimensionen. Um OLAP weiterhin darstellbar zu machen wird normalerweise als Modell des
3-dimensionalen Würfels benutzt.
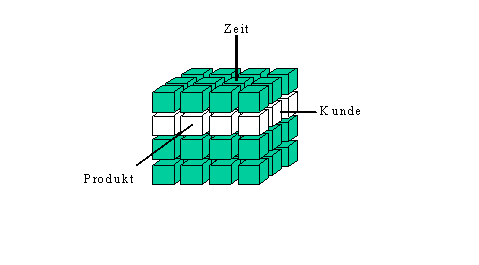
Eine Zelle enthält z.B. den Umsatz zu einem Produkt, das in einem Monat an einen
Kunden verkauft wurde. Gedanklich sind für Analysen noch mehr nachvollziehbare Dimensionen möglich auch wenn
das über das geometrische Vorstellungsvermögen nicht mehr abzubilden ist.
Die sinnvolle Grenze soll zwischen 9 und 13 Dimensionen liegen
Diese mehrdimensionale Erweiterung des 3-dimensionalen Datenwürfelmodells
nennt sich "Hypercube"
Die verschiedenen OLAP - Werkzeuge differenzieren sich dabei nach
...
- MOLAP = multidimensionalem OLAP
- ROLAP = relationalem OLAP
- HOLAP = hybridem OLAP also einer Kombination der beiden anderen
Techniken
top
Datenmodelle
-
Starschema (ROLAP I)
Vor dem Hintergrund ...
- im Laufe der Zeit extrem große Datenmengen speichern zu müssen und
parallel dazu das Änderungsvolumen bezüglich Inhalte und Strukturen zu beherrschen, das durch die Dynamik
der wechselnden Geschäftsanforderungen entsteht sowie
- ein akzeptables Abfrageverhalten zu erreichen
gilt das relationale aber weitgehend denormalisierte Starschema als
geeignetes Modell für die Basisschicht des DataWarehouse.
Das Starschema - also der relationalen Ansatz der
DataWarehousemodellierung - besteht aus einer Basistabelle der Fakt-Tabelle und beigeordneten
Referenztabellen den Dimensionstabellen, die zusammengesetzt als Stern vorstellbar sind.
Fakten "repräsentieren physische Transaktionen zu einem Zeitpunkt"
z.B. Umsatz und Absatz eines Kunden, eines Produkts, eines Tages, sind somit die tiefste Informationsebene,
ändern sich in Normalfall nicht und machen ca. 70% des Datawarehouse-Datenbankvolumens
aus.
Dimensionsdaten dienen dazu die Informationen der Fakt-Tabelle zu
analysieren. Sie sind beschreibende Attribute oder hierarchische Beziehungen den Schlüsseln der
Fakt-Tabelle z.B. Branche, Konzern, Kreis des Kunden. Dimensionsdaten sind regelmäßigen Änderungen
unterworfen, weshalb sie in ihrem Aufbau auf diese Anforderung zugeschnitten sein müssen. Das ist allein
dadurch gewährleistet, daß sie einen nur relativ geringen Anteil am Datenvolumen haben.
Beispiel eines Starschema
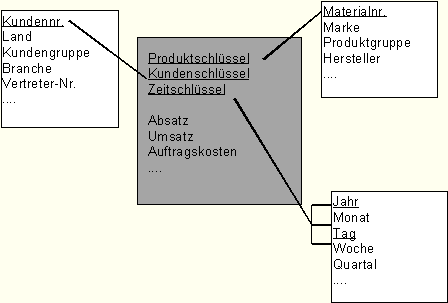
Ändert sich z.B. die Marke zum Produkt, muß nur die entsprechende
Dimensionstabelle verändert werden, die Fakten bleiben erhalten und müssen nicht umgebucht
werden.
-
Snowflake-Schema (ROLAP II)
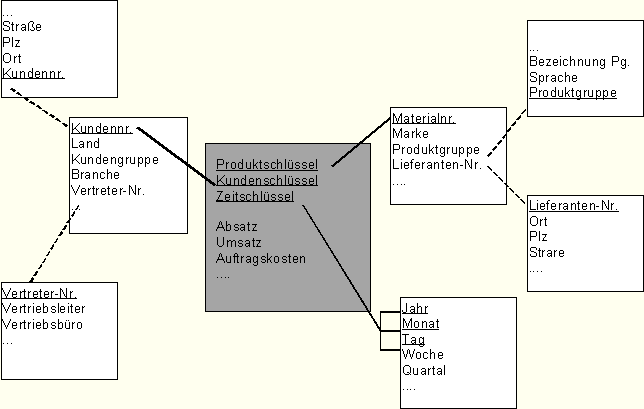
Eine Erweiterung des Starschemas ist das Snowflakeschema. Hiermit können
weitere Attribute der Dimensionsschlüssel bzw. Attribute von Attributen in das Datenmodell und somit in das
Abfragemodell eingebunden werden ohne daß sich der Umfang der Dimensionstabellen so erweitert, daß der
Aufwand die Dimensionstabellen zu aktualisieren zum Engpaß wird. Die Dauer von Abfragen über diese
ausgelagerten / normalisierten Strukturen erhöht sich natürlich durch die weiteren
Verknüpfungen.
Tabellen mit Attributen, die nicht direkt eine Bezug zu Werten haben
-auch im Sinne von Stammdaten - werden auch als Lookup-Tabellen bezeichnet.
Die "Kunst" liegt also darin das Modell so zu gestalten, daß alle für die
Recherche notwendigen Attribute so verteilt sind, daß die Performanz der Abfrage aus auch die Last bei den
Ladevorgängen entsprechend berücksichtigt wird.
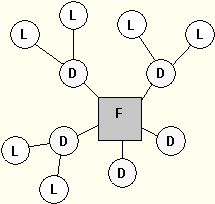
Beispiel eines Snowflakeschema
-
multidimensional (MOLAP)
Multidimensionale Datenbanken (MDDB) sind speziell für Abfragen
entwickelte proprietäre Methoden und Technologien. Die Informationen für die zum Modellierungszeitpunkt
betriebswirtschaftlichen Sichten / Dimensionen werden in speziellen herstellerindividuellen Strukturen so
implementiert und softwaretechnisch unterstützt, daß alle möglichen Abfragekombinationen kalkuliert und
technisch vorbereitet sind. D.h . alle Sichten in jeder Dimension und Verdichtung des "Datenwürfels" werden
gespeichert. Somit der der logische Ansatz des Hypercubes physikalisch 1 : 1
abgebildet.
Beispiel:
Rohdaten
|
Produktnr.
|
Kundennr.
|
Tag
|
Umsatz
|
|
WMV4711
|
K00001
|
05.01.1998
|
100.- DM
|
|
WMV4711
|
K00002
|
05.01.1998
|
200.- DM
|
|
WMV4712
|
K00002
|
05.01.1998
|
100.- DM
|
Multidimensionale Speicherung
|
Produktnr.
|
Kundennr.
|
Tag
|
Umsatz
|
|
WMV4711
|
K00001
|
05.01.1998
|
100.- DM
|
|
WMV4711
|
K00002
|
05.01.1998
|
200.- DM
|
|
WMV4712
|
K00002
|
05.01.1998
|
100.- DM
|
|
WMV4711
|
|
05.01.1998
|
300.- DM
|
|
WMV4712
|
|
05.01.1998
|
100.- DM
|
|
K00001
|
05.01.1998
|
100.- DM
|
|
K00002
|
05.01.1998
|
300.- DM
|
|
|
05.01.1998
|
400.- DM
|
Das führt dazu, daß Anfragen an das System extrem optimiert und somit
schnell abgewickelt werden können. Mit gleicher Effizienz können (temporär) zusätzliche Informationen
hinterlegt werden, was Werkzeuge für diese Methoden besonders geeignet macht komplexe Analysen und
Simulationsvorgänge durchzuführen und schnell durch das System im OLAP-Sinne zu navigieren (Slice and dice,
drill down).
Der Preis dafür ist, daß solche Systeme schwer skalierbar sind z.B. beim
Einführen von neuen Dimensionen oder dem Verändern bzw. Erweitern von bekannten
Dimensionen.
Ebenso erhöht sich das Speichervolumen dieser Datenbankform erheblich, da
alle Dimensionsinhalte Dimensionskombinationen und Verdichtungsstufen redundant vorgehalten
werden.
Das Volumen der Rohdaten also der tatsächlich über die Geschäftsvorfälle
entstandenen Kombinationen von Dimensionsinhalten wird auf das maximal mögliche erweitert und diesen
Kombinationen dann nur noch Werte zugeordnet.
Dadurch wird ebenfalls der Lade- bzw. Updateprozess belastet und
verlängert.
Das physikalische multidimensionale Modell - es gibt auch virtuelle
multidimensionale Würfel, die temporär aus einer relationalen Datenbasis entstehen - ist somit geeignet für
spezielle Aufgabenstellungen im Bereich der Analyse mit abgegrenztem Datenvolumen also für bestimmte
Lösungen mit Data-Marts oder Würfel aus Aggregationen.
- Starflake-Schema
top
Auswertungsmethoden
Zur Auswertung der (dimensional) gespeicherten Daten gibt es grundsätzlich 3
Methoden.
- Reporting
Hier sind Werkzeuge zusammengefaßt, die sich für Standardberichte /
Standardreporting / Standardlisten oder Adhoc-Querys eignen also für hinterlegte oder adhoc gebildete, aber
fest formulierte Fragestellungen an das DataWarehouse. Diese können dann in verschiedenen Formen aufbereitet
und dargestellt werden.
- Data Mining
Für Data Mining benötigt man spezielle Werkzeuge, die sich Techniken wie
neuronalen Netzen oder künstlicher Intelligenz bedienen und damit in bestimmten Datenbereichen nach Trends
und Mustern zu suchen. Werden solche aufgezeigt, sollen Zusammenhänge entdeckt werden können, die so aufgrund
komplexer Informationsverteilung nicht offensichtlich wären. Sie können der Ausgangspunkt für neue
strategische Erkenntnisse und Maßnahmen werden.
-
Datenanalyse - OLAP
Die Ergebnisse der Analysefunktionen sollen dem Anwender (graphisch)
anschaulich gemacht werden und es soll ihm ermöglicht werden die Betrachtungsweisen weiter schnell und
einfach zu verändern.
- Slice&Dice
Das Herausschneiden eines bestimmten Ausschnitts z.B. alles zu einem
Land (Slice) und das Drehen, Kippen oder Würfeln der Sichten auf die Daten, mal nach Kunde, mal nach
Produkt, mal nach Zeit ...(Dice).
- Drill down
Das "Abtauchen" in eine detailliertere Sicht z.B. wie verteilt sich der
Umsatz meiner Produktgruppe auf die einzelnen Produkte.
- Drill up
Das Gegenteil von Drill down und somit das Wechseln auf eine
übergeordnete Ebene.
- Roll up
Der Einstieg in einer tieferen Ebene und Erweitern zu höher
verdichteten Betrachtungsweisen. (Oft analog zu drill up benutzt)
- Drill across
Das wechseln der Umgebung auf der selben Betrachtungsebene z.B. zuerst
analysiert man Kunde-Produktbeziehungen eines Landes, dann wechselt man das Land.
- Drill through
Mit dem Ergebnis einer Analyseumgebung (Datenwürfel) in eine andere
Umgebung wechseln und dort die Analyse fortsetzen.
- Exceptions
bzw. Ampelfunktionen: Damit können Grenzwerte und Regeln definiert
werden, die auf einer höheren Ebene hinweisen, daß der hier gezeigte Wert auch von "Ausreißern" bestimmt
wurde. So kann z.B. beim Betrachten von Vertriebszentren schnell erkannt werden, daß ein Vertriebszentrum
nur deshalb im aktuellen Monat etwas schlechter ausfällt weil ein bestimmter Großkunde diesmal
ausfällt.
- ABC-Analysen
Welcher Anteil von Kunden/Produkten haben welchen Anteil am
Ertrag.
- Ranglisten
Die Top x meiner Betrachtung.
top
|