-
Extraktion und Einfügen
- Extraktion = Holen der Daten aus den Quellsystemen bzw. Organisieren
der Bereitstellung der Daten durch die operationalen Systeme inklusive des
File-Transfers.
- Koordination von verschiedenen solchen Vorgängen.
- Mapping der Inhalte = Zuordnung der Quellen / Quellfelder zu den
Zielbereichen / Zielfelder.
- Filtern und Prüfen der Daten
- Einfügen in temporären Speicherbereich

-
Aufbereiten u. Umwandeln
Die Daten müssen nun dahingehen transformiert werden so daß sie für hohe
Abfragegeschwindigkeiten und große Datenmengen geeignet sind.
- Umwandeln in DW-spezifische Strukturen (Starschema)
- Prüfen der Daten gegen die bestehende Datenbasis.
- Laden der Daten in die tiefste Speicherebene entsprechend der
innerbetrieblichen Regeln (Aggregationsverhalten)
- Sichern u. Archivieren
Sichern von historischen Daten und Strukturen zur schnellen
Rückspeicherung.
-
Beschleunigung der Abfrageleistung
- (Automatisch) Erweitern und Aktualisieren von Zusammenfassungen /
Aggregationsstufen
- Erstellen / Aktualisieren von Indices
- Erstellen / Aktualisieren / Verteilen von Replikationen
(Data-Marts)
- Erstellen von Abfragestatistiken zur Überprüfung von sich ändernden
Abfrageprofilen
-
Steuerung und Verwalten der Abfragen
- Inhaltliche Steuerung der Anwenderabfragen (Welche Anforderung betrifft
welche Tabellen, Aggregationen, Data-Marts ...)
- Zeitliche Steuerung der Anwenderabfragen (Welche Anforderungen müssen
zeitlich verschoben werden z.B. als Batch)
- Vermeiden von Systemüberlastung einer Abfrage
(Killerabfragen)
-
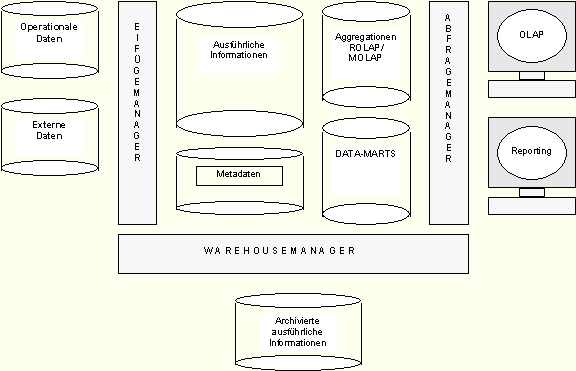
Ausführliche Informationen
Die ausführlichen Informationen beschreiben die tiefste Speicherebene im
DataWarehouse und ergeben sich aus den Aktivitäten im Geschäftsablauf, auf die noch in ihren
Einzelergebnissen zurückgegriffen werden muß. Um das Datenvolumen bewältigen zu können werden die gesamten
Einzelinformationen nur für einen bestimmten Zeitraum vorgehalten und fließen dann in die nächste Ebene der
Aggregationsstufen ein.
Sie können auch bei der Verfolgung einer "wellenförmigen Strategie" bald
archiviert werden und bei Bedarf wieder einfließen (z.B. bestimmte Monate des Vorjahres). Diese Strategie
ist zwar günstiger für das Speichervolumen, erweist sich wahrscheinlich aber als problematisch, wenn
Strukturen und/oder Inhalte des DataWarehouse einer regelmäßigen Änderungsfrequenz unterworfen sind und
diese Änderungen auch historisch nachvollzogen werden sollen.
Welche Methoden existieren die ausführlichen (und andere) Informationen in
der Datenbasis abzubilden ist im Abschnitt "Datenmodelle" im Kapitel "OLAP" beschrieben.
-
Aggregationen
Aggregationen/Verdichtungen sind zusammengefaßte Informationen repliziert
aus der tiefsten Speicherebene des DataWarehouse und repräsentieren eine bestimmte vordefinierte Sicht auf
das DataWarehouse also z.B. alle Kunden mit ihren Produktgruppen oder man hält tagesaktuelle Daten für 3
Monate, ansonsten aber nur monatsaktuelle Daten vor.
Eine Aggregation kann auch im Sinne einer logischen
Partitionierung 1 1 Die technische
Partitionierung / Verteilung von Tabellen, Indices ...(auch nach logischen Gesichtspunkten z.B. je
Vertriebsgesellschaft) ist natürlich auch ein notwendiger Bestandteil der DataWarehouse-Architektur. Das
unterstützt u.a. auch ein Konzept zur auszugsweisen Datensicherung und
-wiederherstellung.eingesetzt werden z.B. alle Kunden mit
ihren Produktgruppen einer einzelnen Vertriebsgesellschaft.
Ziel des Vorgehens Aggregationen einzusetzen ist es die Abfrageleistung bzw.
die Antwortzeiten zu erhöhen und die Systembelastung durch Abfragen zu verringern.
Die Entscheidung für eine bestimmte Aggregation und deren Struktur der
zusammengefaßten Information ergibt sich ...
- aus den zu erwartenden Abfragestrategien der Anwender.
- aus dem Faktor der Datenverringerung, der sich für eine Aggregationsebene
ergibt.
Da sich sowohl das Anwenderverhalten verändert, als auch sich ändernde
Datenkonstellationen sich auf den Verdichtungsfaktor auswirken, unterliegt der Einsatz von Aggregationen
einem permanenten Verwaltungsaufwand durch ...
- technische Aktualisierung der Verdichtungen, wenn sich die Datenbasis
ändert / erweitert (Automatisierung über den Warehousemanager)
- Beobachtung des Anwenderverhaltens und der daraus abgeleiteten
Umstrukturierung der Aggregationen und deren Neuaufbau.
Also:
- Je mehr Aggregationen desto höhere Abfrageperformanz aber ...
- Je mehr Aggregationen desto höherer Speicherbedarf, höherer
Administrationsaufwand, längere Lade-, Aktualisierungszeit. ...
1 Die technische Partitionierung / Verteilung von Tabellen, Indices
...(auch nach logischen Gesichtspunkten z.B. je Vertriebsgesellschaft) ist natürlich auch ein notwendiger
Bestandteil der DataWarehouse-Architektur. Das unterstützt u.a. auch ein Konzept zur auszugsweisen
Datensicherung und -wiederherstellung.
-
Data-Marts
Data-Marts sind Untergruppen des Informationsgehalts eines DataWarehouse
- unabhängig von ihrer physikalischen Größe -, die aggregiert oder ausführlich in einer eigenen
Datenbank gespeichert werden.
Data-Marts sollten so definiert und abgegrenzt sein, daß sie fast das
gesamte Anforderungsprofil abdecken können und nur im Einzelfall auf Informationen des restlichen
DataWarehouse zurückgegriffen werden muß.
Data-Marts werden normalerweise eingerichtet ...
- für funktionale oder Abteilungsbereiche, die evtl. auch geographisch
weiter entfernt sind.
- für den Einsatz bestimmter Werkzeuge, die eine eigene Datenhaltung
benötigen z.B. für eine multidimensionale Datenanalyse.
Die Administration von Data-Marts insbesondere das Füllen bedeutet einen
gewissen nicht zu unterschätzenden zeitlichen Aufwand, was evtl. beim Einsatz von mehreren
unterschiedlichen Werkzeugen oder mehrfachen Installationen eines Werkzeugs mit eigener Datenbank
problematisch werden kann.
Physikalische Data-Marts im logischen DataWarehouse oder Data-Marts
nur aus einem physikalischen DataWarehouse ?
Der Ansatz "think big start small" könnte zur Schlußfolgerung führen, daß es
reicht das DataWarehouse nur im logischen Sinn zu sehen und daß die physikalische Abbildung in den
verschiedenen Datenbanken der Data-Marts erfolgt.
Aber ...
- es ist schwierig Daten inhaltlich konsistent zu halten, wenn sie nicht
physikalisch aus einer Datenbank kommen.
- es gestaltet das Abfragemanagement aufwendig und schwierig, wenn doch
unternehmensweite Zusammenhänge bzw. über die Data-Marts greifende Anforderungen häufiger gefordert
sind.
Bei Hardwareengpässen sollte zumindest das Füllen von Data-Marts über das
DataWarehouse erfolgen.